
TLDR: To build a global onchain economy, we need to scale to keep gas fees under one cent. Our goal for 2025 is to reach a gas target of 250 Mgas/s — a 100x increase from where we started. In Q1, we hit a major milestone: 25 Mgas/s, 10x from launch. We’re now on track to reach 50 Mgas/s by the end of Q2. This quarterly review provides a status update on critical scaling bottlenecks, and our progress towards eliminating them.
Base’s mission is to build a global onchain economy that increases innovation, creativity, and freedom. To achieve this, one of Base’s five strategic pillars for 2025 is to scale Base and drive gas fees down so that everyone, everywhere can come onchain. In 2024, we scaled Base to 20 Mgas/s — nearly 10x of where we started. This year, our goal is to scale Base’s gas target to 250 Mgas/s — increasing Base’s capacity to handle more transactions, more builders, and more people onchain.
At the beginning of this year, we published our approach to scaling Base in 2025. Today, we’re sharing an update on our progress thus far, and what’s top of mind as we continue to increase Base’s throughput and eliminate key bottlenecks to accelerate further.
Bottleneck Review
In our previous scaling blog, we outlined the scaling bottlenecks we’re working to remove to accelerate towards our 2025 goal of 250 Mgas/s. Here, we’ll provide updates on these bottlenecks going into Q2.
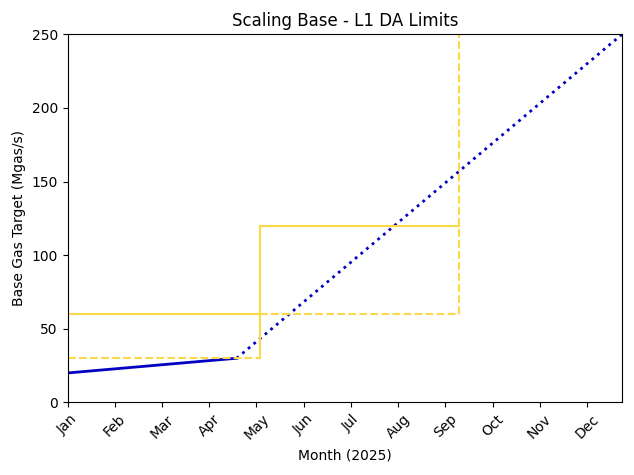
Bottleneck 1 - L1 Data Availability
Blobspace has remained at capacity for several months. The Pectra hard fork, which activates on Ethereum Mainnet on May 7th, will double blobs and provide more runway for L2s to scale. Doubling blobspace in Pectra was a major goal of the Base team throughout the past year, and we are excited to see that come to reality.
We know, and have known for a while, that this is only a temporary win — the ecosystem will likely use up that blobspace shortly after activation. Therefore, we continue to invest heavily in PeerDAS, in collaboration with the Ethereum Foundation, various EL and CL clients, and other L2s, to unlock a much larger increase in L1 data availability.
PeerDAS will be included in Fusaka, the hard fork following Pectra, shipping in Q3 this year. This timeline is aggressive, but with the right focus and investment, we can achieve this as a major unlock for scaling Ethereum. We believe that timelines slipping for Fusaka is the biggest risk to Ethereum successfully enabling support for mass adoption in the coming year.
If PeerDAS ships according to schedule, we expect the updated bottleneck graph to look like the following.
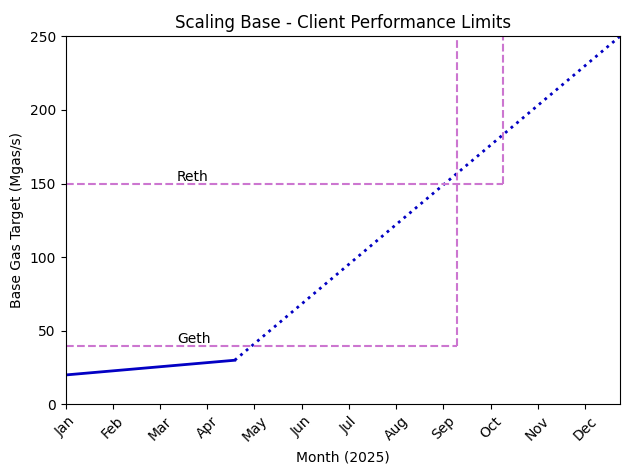
Bottleneck 2 - Client Execution Speed
Client execution speed can be broken into two categories: block building performance (time for the sequencer to create a block) and validator performance (time for a validator to sync a block). Given that execution client performance underlies both of these, we continue to treat them as one bottleneck.
Our main focus to address client execution speed is to fully decommission Geth Archive nodes. We have migrated almost all nodes, including the sequencer node, off Geth Archive, and encourage others to do the same. There is only one remaining dependency on Geth Archive related to fault proofs that will soon disappear as well.
A major source of EL performance constraints — that we previously identified and continue to validate with real world data — is the significant latency resulting from database accesses on local disk. We are actively prototyping and will soon share more details around a solution to reduce this latency.
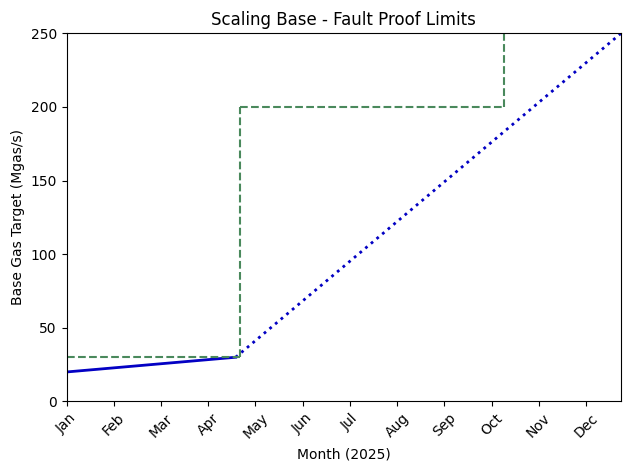
Bottleneck 3 - Fault Proofs
By the end of April, Base will upgrade to a new version of Cannon, the virtual machine that underlies Base’s fault proof system today. The updated version, built by OP Labs, expands Cannon’s memory architecture from 32-bit to 64-bit, and has built-in multithreading support. These two improvements provide a big scaling win by almost completely removing the two scaling bottlenecks of the current fault proof system: memory usage and challenger runtime.
Our initial review shows that the new Cannon, which we are calling MT64Cannon, completely removes the memory constraints we had identified in Cannon and significantly reduces challenger runtime as well.
To ensure MT64Cannon continues to support Base’s scaling goals, we are tracking metrics such as challenger success / failures, challenger runtime, memory usage, and MIPS instruction count.
With our big push to migrate to Reth, we have identified fault proofs as one of the final dependencies on Geth. Because of this, we have significantly invested in adding Reth compatibility for op-program to remove this final dependency. This work is code-complete and should land soon.
While MT64Cannon will likely support our 2025 scaling goals, it will not support Base scaling forever. We are currently evaluating more performant alternatives, including fully Reth based fault proof systems.
Bottleneck 4 - State and History Growth
In our last scaling review, we shared that we aim to keep node disk usage, as a proxy for history growth, under 30 TB, a limit based on NVMe SSD drives provided by popular cloud providers today. Geth Archive has surpassed this threshold, another reason why we have completely migrated off Geth Archive. We highly recommend anyone still running Geth Archive nodes to migrate to Geth Full or Reth Archive nodes.
Given the removal of the Geth Archive dependency, we do not anticipate any bottlenecks for scaling to 250 Mgas/s.
Bottleneck Summary
Combining all of the bottlenecks we get the following graph.
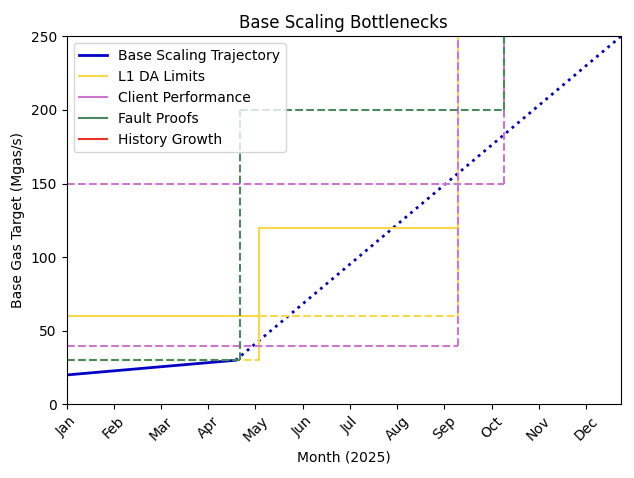
Viewing this compared to the graph from a couple months ago, we see that we have made significant progress towards removing bottlenecks.
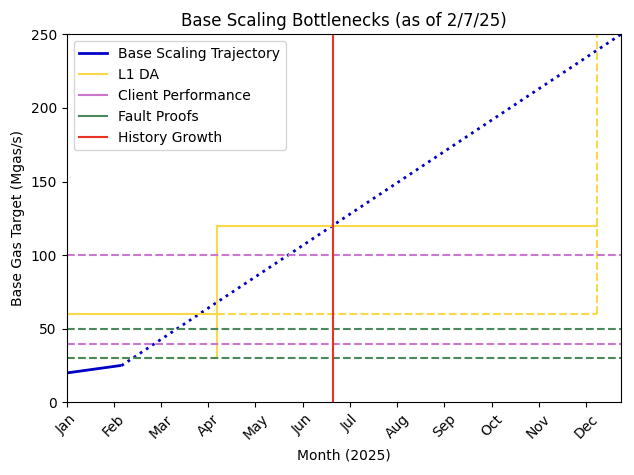
But it’s still Day 1 - there is a lot more work to do to continue enabling Base to scale at the rate we have planned.
Safety and Reliability
A major focus for our team is scaling safely. We have very ambitious scaling goals, but will not push these at the expense of chain safety and reliability.
Over the past six months, we invested significantly into optimizing internal Base infrastructure to ensure it operates reliably as we scale. We established an internal go/no-go process for each time we increase Base’s gas target, which ensures our metrics are healthy prior to the increase.
We are also building a comprehensive benchmarking tool to enable us to validate system performance against the future gas limit we are scaling to, instead of just the current gas limit. This will provide us more confidence in scaling by proactively surfacing unknown unknowns, especially as we do larger gas target increases.
As we accelerate scaling, we want to ensure that in addition to having healthy internal infrastructure, the rest of the ecosystem also remains healthy. Base is already at the scale where not running proper node configurations can lead nodes to fall behind. We have seen instances where our internal nodes kept up with the traffic but we received reports of external nodes falling behind. We recommend all node operators regularly check our docs (docs.base.org) and subscribe to our status page (status.base.org) for the most up to date hardware and client configuration recommendations. It can be assumed that the recommendations we provide on our official docs have passed our benchmarking tests.
Looking Forward
We would not have been able to scale Base to where it is today without the support of many teams across the ecosystem — and we’ll continue to collaborate to scale it further. We hope these efforts to scale Base provide learnings and infrastructure to enable other L2s and the rest of the Ethereum ecosystem to scale.
2025 is the year we scale together. We’re looking for collaboration partners to pursue challenges like shipping PeerDAS and optimizing performance of execution clients and fault proof systems. If you’re interested in working on creative and ambitious scaling solutions to enable the next billion people to come onchain, we’re hiring — and we’d love to hear from you.
Follow us on social to stay up to date with the latest: X (Base team on X) | Farcaster | Discord

